PQuantML
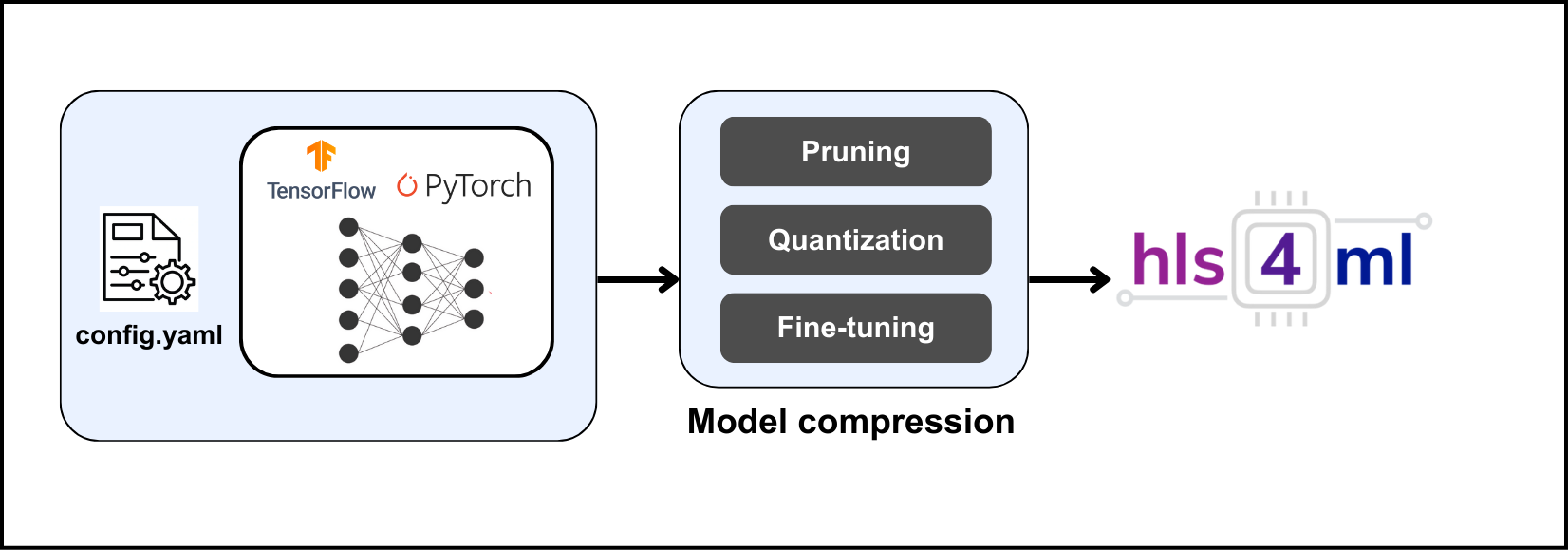
Welcome to the official documentation for PQuantML, a hardware-aware model compression framework supporting:
Joint pruning + quantization
Layer-wise precision configuration
Flexible training pipelines
PyTorch and TensorFlow backends
Integration with hardware-friendly toolchains (e.g., hls4ml)
PQuantML enables efficient deployment of compact neural networks on resource-constrained hardware such as FPGAs and embedded accelerators.
Key Features
Joint Quantization + Pruning: Combine bit-width reduction with structured pruning.
Flexible Precision Control: Per-layer and mixed-precision configuration.
Hardware-Aware Objective: Include resource constraints (DSP, LUT, BRAM) in training.
Simple API: Configure compression through a single YAML or Python object.
PyTorch Integration: Works with custom training/validation loops.
Export Support: Model conversion towards hardware toolchains.